How to Upload Data in Kibana Windows 10
Check Logs with Kibana¶
Kibana is the web based front end GUI for Elasticsearch. It tin exist used to search, view, and collaborate with data stored in Elasticsearch indices. Advanced data analysis and visualize can be performed with the help of Kibana smoothly.
We take completed an finish to end production environement ELK stack configuration with the previous affiliate. In this affiliate, we will employ Kibana to explore the collcted data.
Index Patterns¶
The first fourth dimension y'all login Kibana (http://<IP or FQDN>:5601), a hint every bit In order to visualize and explore data in Kibana, you'll need to create an index design to retrieve data from Elasticsearch will be shown on the top of the folio and a shortcut to create an index blueprint is shown:
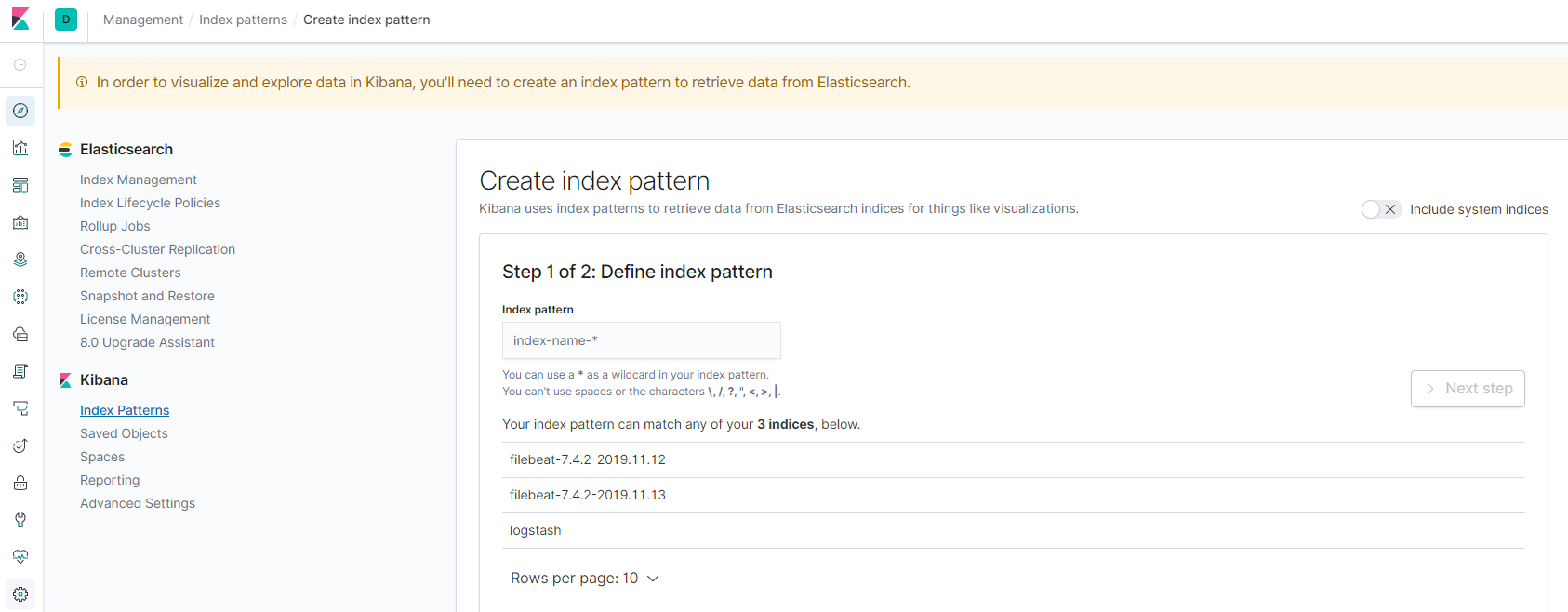
An alphabetize blueprint tells Kibana which Elasticsearch indices you want to explore. It can match the name of a single index, or include a wildcard (*) to lucifer multiple indices. But look, what is an index? An index is a kind of data organisation mechanism on how your information is stored and indexed. Every single piece of data sent to Elasticsearch actually is targging at an alphabetize (stored and indexed). To retrieve information, nosotros of class need to let Kibana know the information souce (index patterns). Please refer to this weblog for more than details on alphabetize.
To create index patterns, it is recommended to behave the operation from the Management view of Kibana:
-
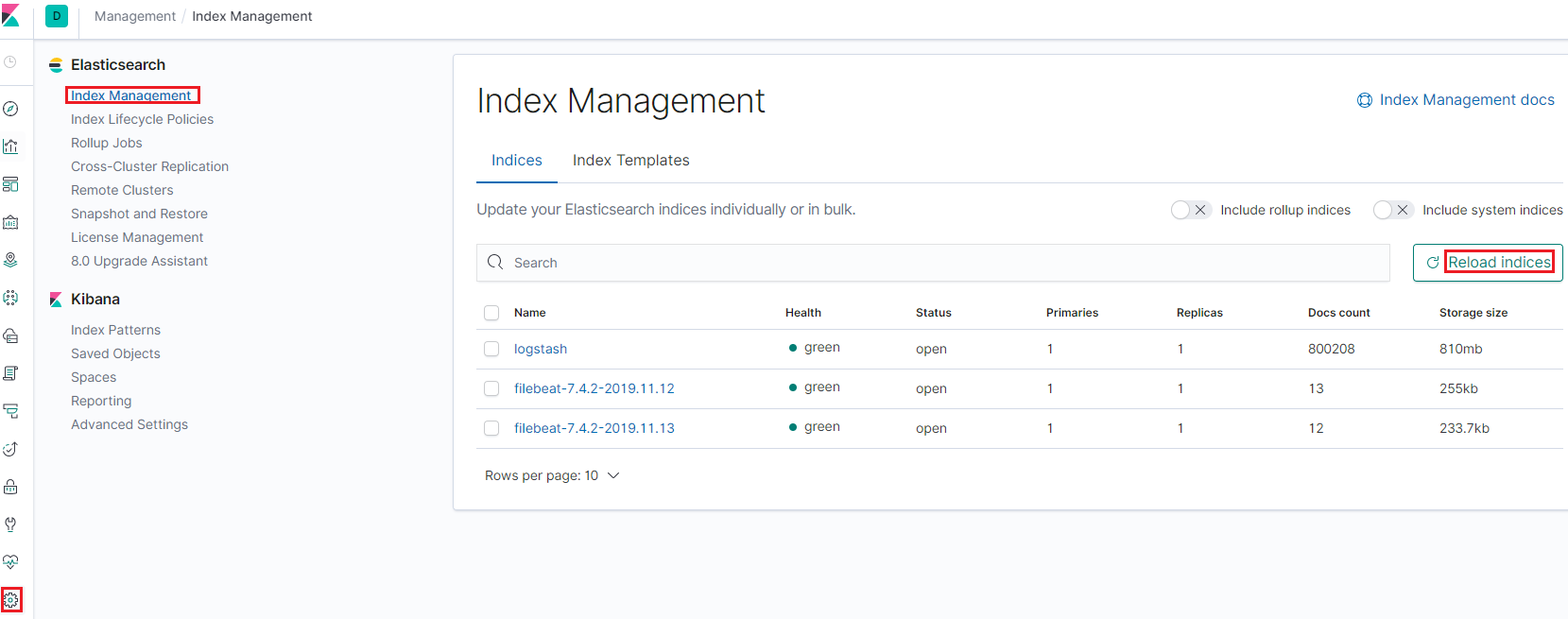
Get to the "Management" view, then bank check available indices (reload indices if there is none):
-
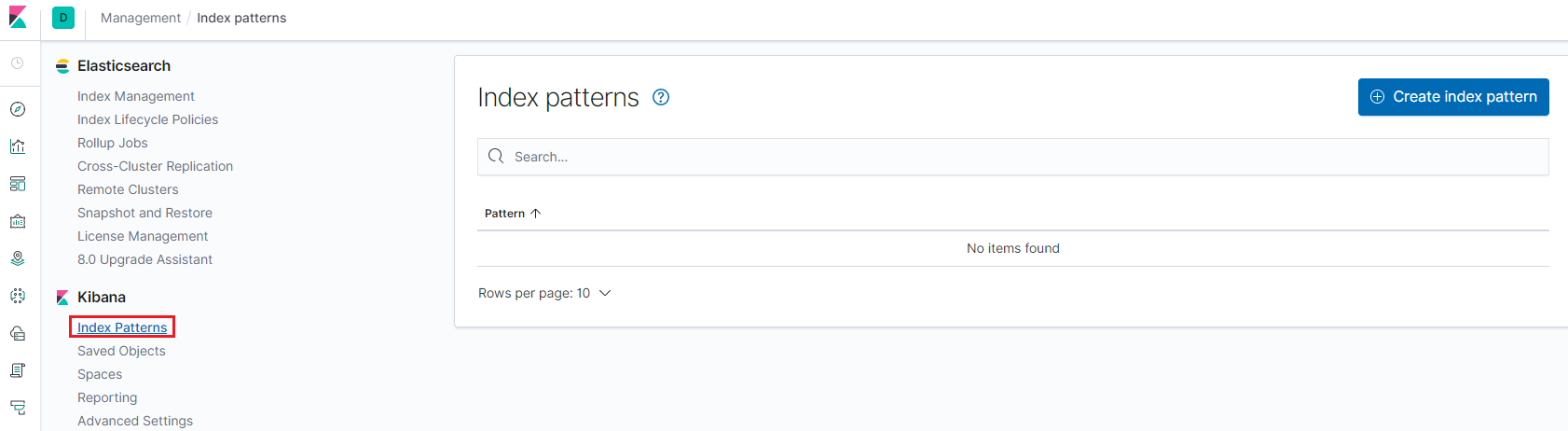
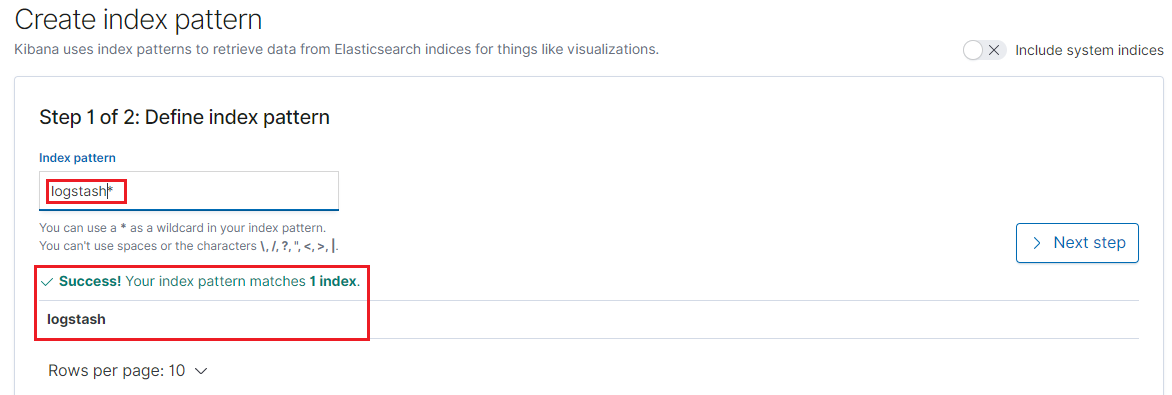
Based on the name of existing indices, created index patterns:
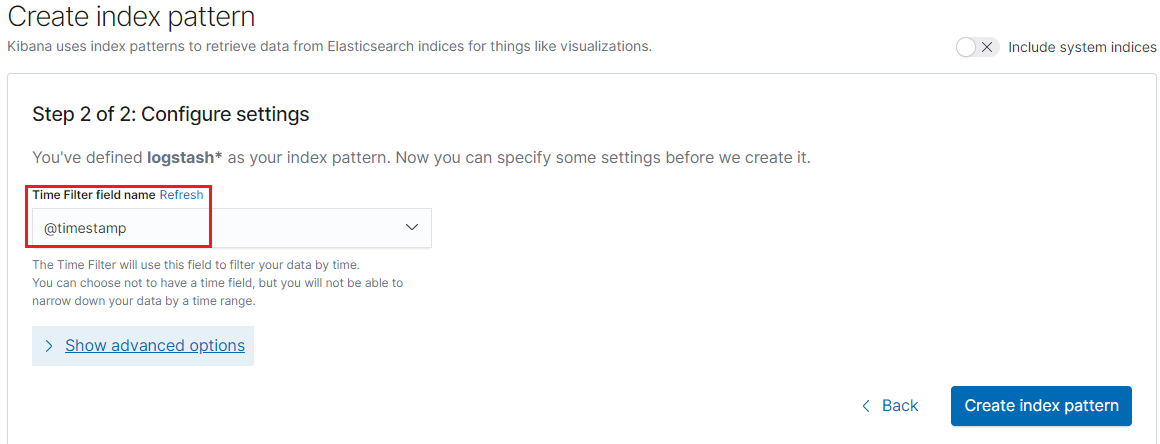
-
We create index patterns for logstash and filebeat:
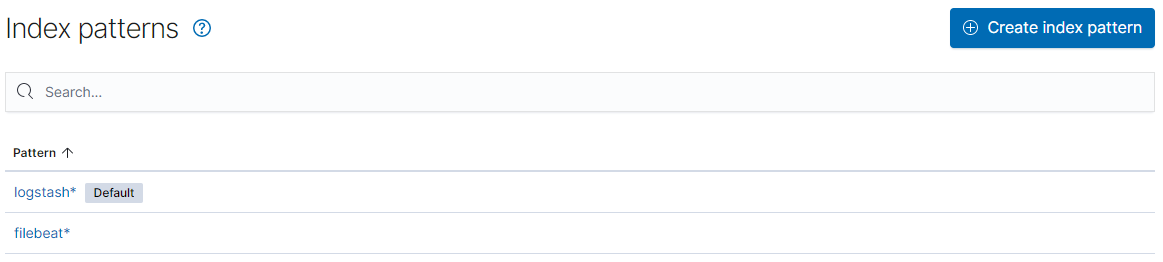
After creating index patterns, nosotros can start exploring information from the Discover view by selecting a pattern:
KQL Basics¶
To smoothen the exprience of filtering logs, Kibana provides a uncomplicated language named Kibana Query Lanagure (KQL for brusque). The syntax is really straightforward, nosotros volition introduce the basics in this department.
Simple Match¶
Syntax:
< field name > : < word to match > Example:
- response:200
- Search documents (log records) which have a field named "response" and its value is "200"
Quotes Match¶
Syntax:
< filed proper name > : "<words to match>" Example:
- message:"Quick chocolate-brown fox"
- Search the quoted string "Quick chocolate-brown fox" in the "message" field;
- If quotes are not used, search documents which have word "Quick" in the "message" field, and have fields "brown" and "fox"
Complicated Match¶
Syntax:
- Logical combination: and, or, not
- Group : ()
- Range : >, >=, <, <=
- Wildcard : *
Examples:
- response:200 and extension:php
- Lucifer documents whose "response" field is "200" and "extension" field is "php"
- response:200 and (extension:php or extension:css)
- Lucifer documents whose "response" field is 200 and "extension" field is "php" or "css"
- response:200 and not (extension:php or extension:css)
- Match documents whose "response" field is 200 and "extension" field is non "php" or "css"
- response:200 and bytes > one thousand
- Friction match documents whose "response" field is 200 and "bytes" field is in range larger than "thou"
- machine.bone:win*
- Lucifer documents whose "car" field has a subfield "os" and its value commencement with "win", such as "windows", "windows 2016"
- machine.os.*:"windows 10"
- Friction match documents whose "machine" field has a subfiled "os" which also has subfileds and any of such subfields' value contains "windows 10"
Explore Real Data¶
We accept introduced alphabetize patterns and KQL, it is time to have a expect at real information in our production setup. All log records will exist structured equally JSON documents equally we previously introduced, and Kibana volition show a summary for related indices as beneath once an alphabetize pattern is selected:
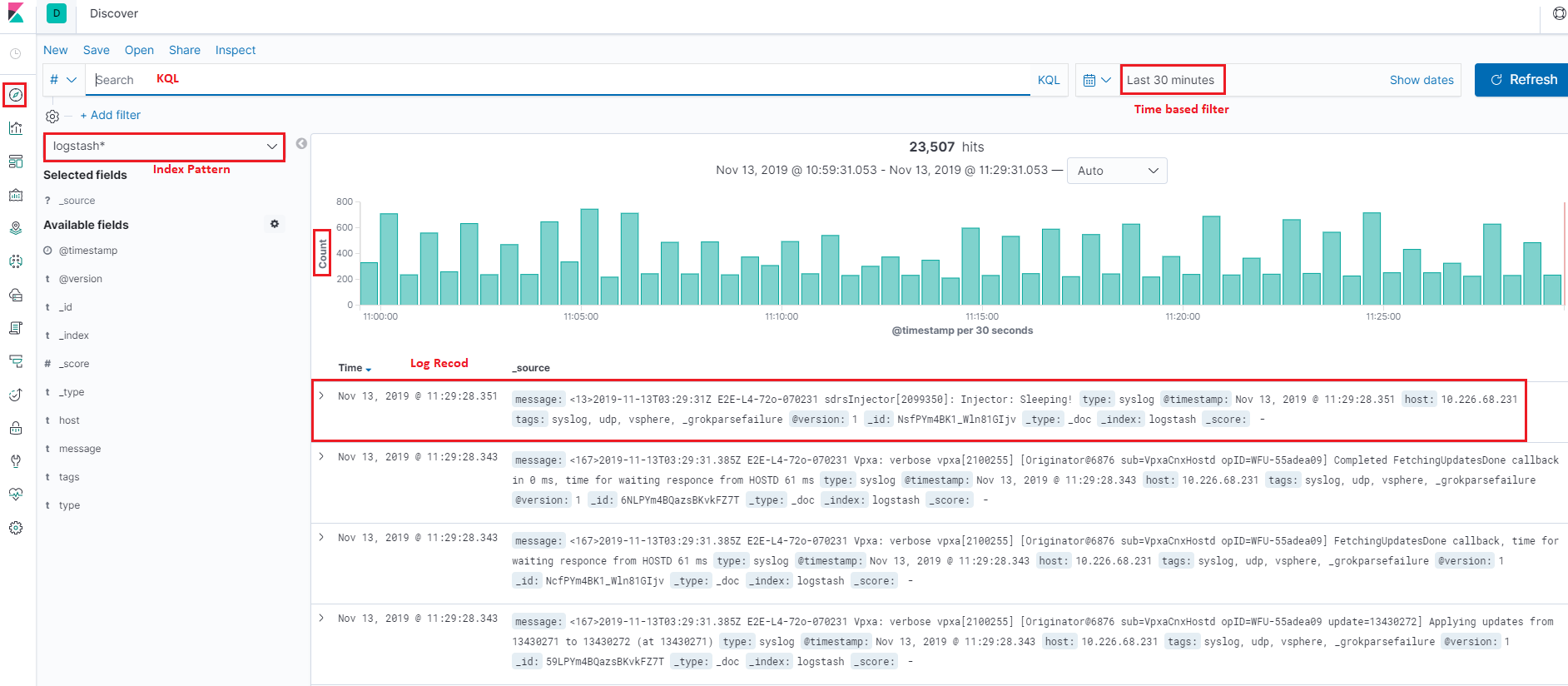
As we said, log records will be formated/structured equally JSON documents. Bug how? Actually, there is term called mapping, which performs the translation work from the original format (such equally text) to JSON. Since logstash and filebeat already accept internal mapping divers, we do not need to care about the details. What we should know is that the JSON documents from different data input (logstash, filebeat, etc.) may be unlike because of the mapping. For more data on mapping, please refer to the offical introduction.
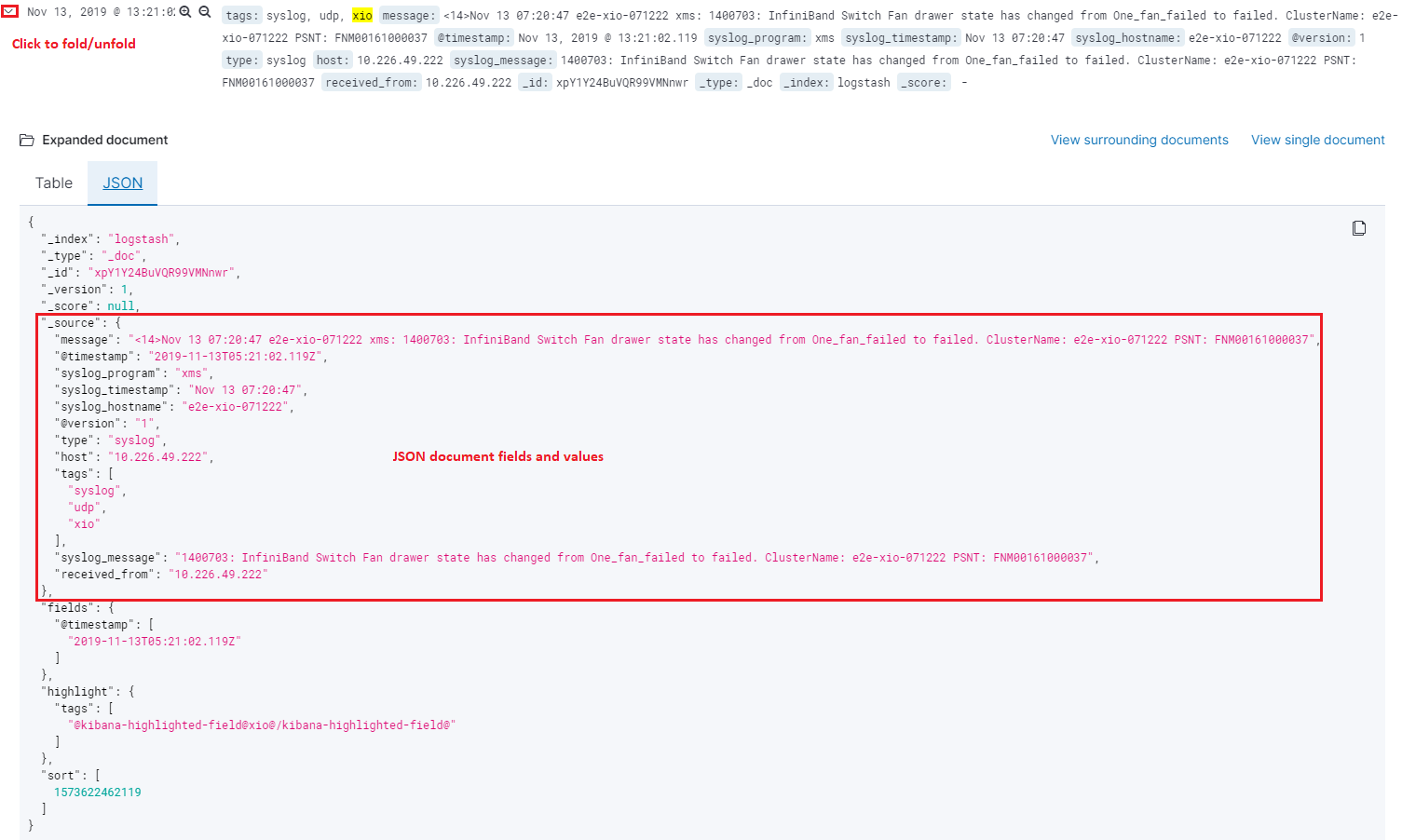
Below are JSON document samples from different input type:
-
logstash:
-
filebeat:
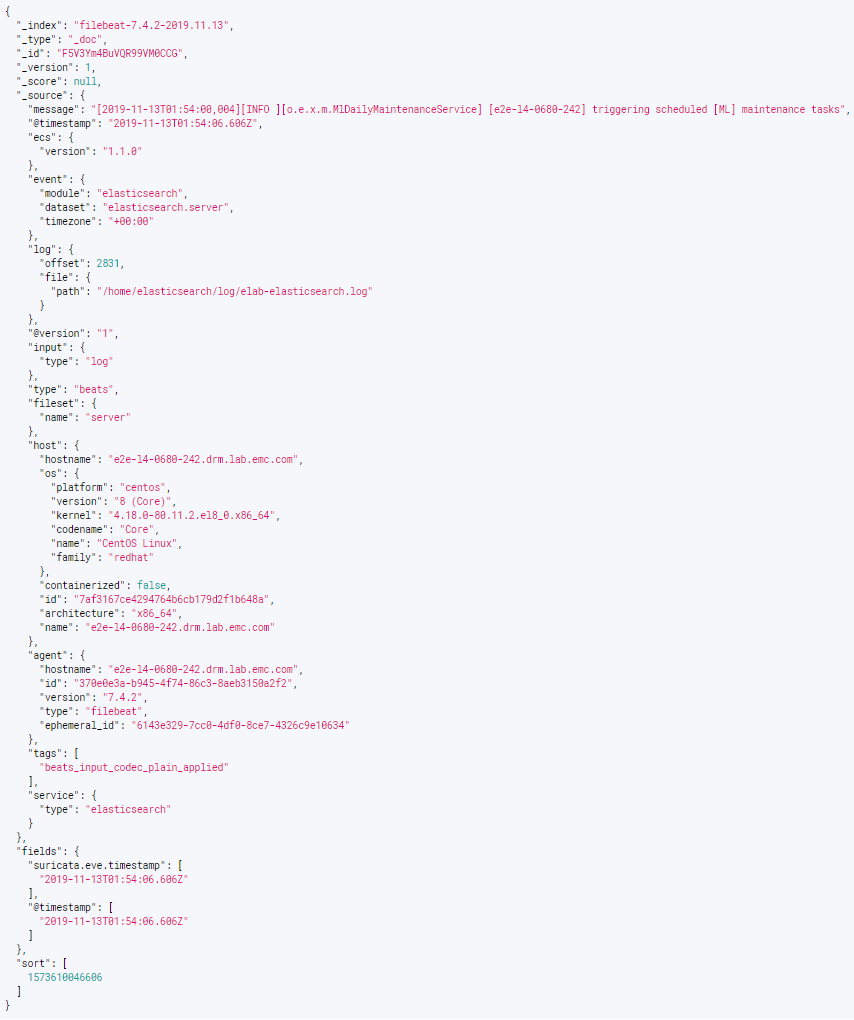
Based on the samples, nosotros meet each document consist of a few fields. These fields are the cardinal for filtering. For example, we can filter logs which are from "xio" with hostname "e2e-xio-071222" and not related with "InfiniBand" as below:
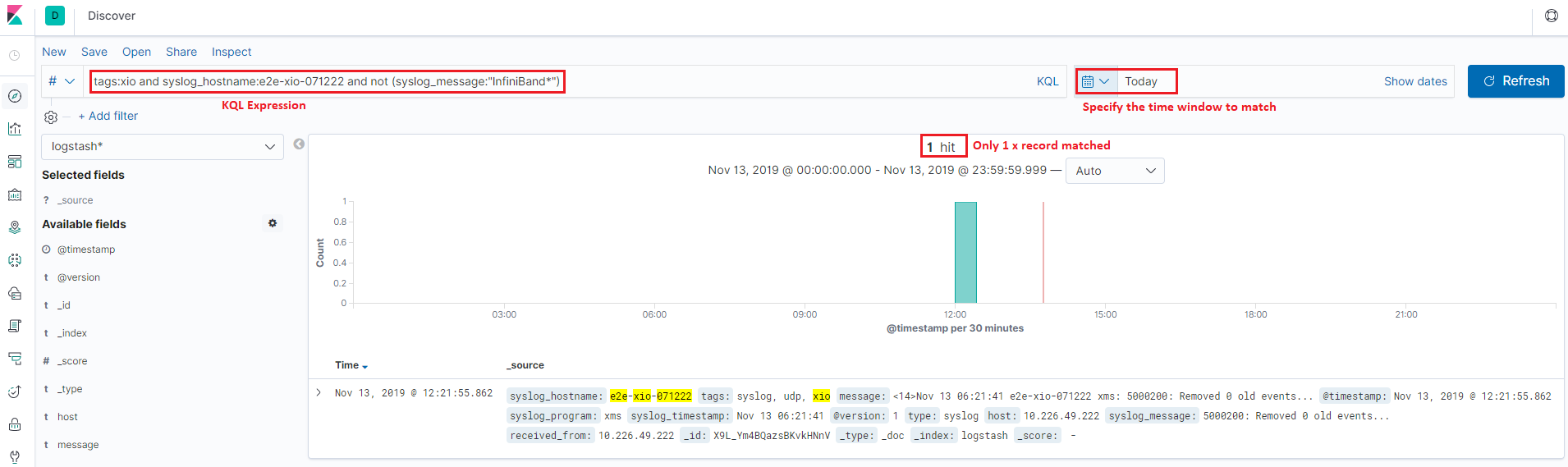
Pretty piece of cake, right? In that location is no more magic for this! Just specify your KQL with fields and value expressions, that is all!
Save Search/Query¶
It is a frequent request that nosotros want to classify logs based on different condtions. Of class, we can achieve this past using unlike KQL expressions, simply keeping inputting KQL expressions is not a comfortable mode. Kibana provides the functions to save your search/query and replay them on demand.
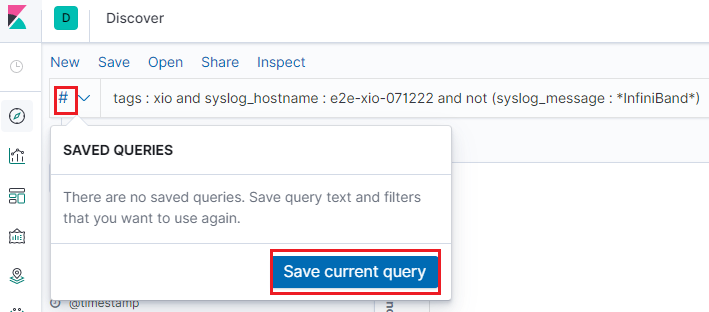
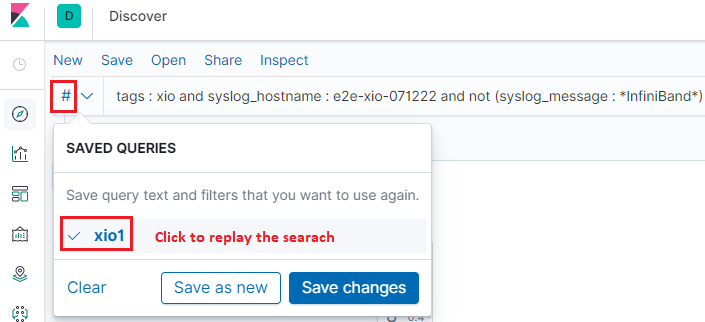
Conclusion¶
Using Kibana explore logs is every bit easy equally we introcued higher up. Although its usage is easy and straightforward, it is powerful enough covering our daily log processing tasks.
Source: https://elastic-stack.readthedocs.io/en/latest/kibana_search.html
0 Response to "How to Upload Data in Kibana Windows 10"
Post a Comment